
I remember when I first looked at the curriculum for Develeap’s 20th bootcamp, I recognized just a few words. From the philosophy of DevOps to the tools it uses, I was completely clueless. I researched the terminology online, but it wasn’t enough for me to understand how all these technologies worked together to create a cohesive system.
All I knew was that the concept itself sounded intriguing but I was afraid that I did not have the proper base of knowledge to attempt this bootcamp. Today, I am very happy that I pushed myself forward despite my self-doubt, because what ultimately mattered was not my existing knowledge but my ability to learn and my curiosity.
After completing the bootcamp and offering advice to several people considering joining, I decided to write an article to give others a clearer picture of what they’re signing up for.
I have prepared a detailed technical overview of the portfolio project for those considering joining our DevOps bootcamp. This overview should provide you with a more concrete understanding of the bootcamp’s content and the skills you’ll develop, helping you to better prepare for the journey ahead.
During the bootcamp, you will create many impressive projects, but the most demanding and rewarding one will undoubtedly be your portfolio project. It will incorporate all the technologies and methodologies you learn during the bootcamp, providing tangible proof of your progress and abilities.
DO-IT
During the portfolio you’ll need to develop an application and build the entire DevOps ecosystem around it: CI/CD, infrastructure, and more. The app itself doesn’t really matter and so my recommendation is to not spend too much time on it. Remember, you’re here to study DevOps, not app development. I opted for a simple todo app with a functional API and two web pages – that was the extent of my “beautiful” app.
The real fun lies in everything surrounding the app. Before diving into the project itself, I need to explain a couple of fundamental concepts in DevOps:
Containerization
Containerization is a lightweight method of packaging and deploying applications along with their dependencies. It allows software to run reliably when moved between different computing environments.
Key points about containerization:
- Isolation: Each container runs in its own isolated environment, ensuring consistency across different systems.
- Portability: Containers can run on any system that supports the container runtime, reducing “it works on my machine” problems.
- Efficiency: Containers share the host OS kernel, making them more lightweight than traditional virtual machines.
- Scalability: Containers can be easily scaled up or down based on demand.
- Consistency: Developers and operations teams work with the same container images, promoting a smoother workflow.
- Speed: Containers can be started and stopped much faster than virtual machines.
While various tools exist for containerization, in the bootcamp we focus on Docker – the industry’s leading solution. Docker allows for the creation of container images, each representing a self-contained, fully functional application with all its dependencies.
We also learn about using Kubernetes, a powerful platform used to orchestrate (essentially manage and control multiple instances of) containers. It’s important to note that Kubernetes isn’t limited to Docker containers; it can work with various container runtimes.
CI/CD
CI/CD (Continuous Integration and Continuous Deployment) is a software development approach that relies heavily on automation to streamline the process of updating and releasing code changes.
Continuous Integration (CI) automates the integration of new code into a shared repository. CI automates the build process, ensuring that the code can be compiled and packaged without manual intervention. It also employs automated testing to verify the functionality of the code as soon as it’s committed. This includes unit tests, integration tests, and other automated checks.
Continuous Deployment (CD) extends this automation further. Once the automated tests pass and the build succeeds, CD systems automatically push the validated code to staging or production environments. This automated pushing eliminates manual deployment steps, reducing the potential for human error and increasing the frequency of releases.
CD can also refer to Continuous Delivery, where the validated code is deployed to staging, but requires human approval before being released to production.
The automation of testing, building, and pushing code is at the heart of CI/CD. It allows developers to catch and fix issues early, ensures consistent build processes, and enables rapid, reliable deployments. This automated pipeline speeds up the development cycle, improves code quality, and reduces the risk associated with releases.
Understanding CI/CD and its focus on automated building, testing, and pushing is crucial because it represents a fundamental shift in how software is developed, validated, and delivered.
Infrastructure as code
Infrastructure as Code (IaC) is a key concept in modern IT operations that applies software development practices to infrastructure management. It involves defining and managing infrastructure using code and automation tools, rather than manual processes or interactive configuration tools.
With IaC, infrastructure configurations (such as networks, servers, and other resources) are described using a high-level descriptive coding language. This code can be version-controlled, shared, and modified like any other software code.
The core principles of IaC include:
- Automation: IaC automates the provisioning and management of infrastructure, reducing manual effort and human error.
- Version Control: Infrastructure configurations are stored in version control systems, allowing teams to track changes, roll back if needed, and collaborate effectively.
- Consistency: IaC ensures that environments are provisioned consistently every time, eliminating configuration drift between development, testing, and production environments.
- Scalability: It becomes easier to scale infrastructure up or down as needed, by simply modifying and redeploying the code.
- Documentation: The code itself serves as documentation of the infrastructure, making it easier to understand and maintain.
In case it wasn’t obvious by now, automation is a big deal in DevOps! The more automation you have, the less chance there is for human error, and you should always strive to automate as much of your work as you can.
Now, let’s dive into the project itself
Here is the architecture diagram of my project
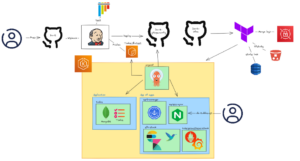
My project focuses on establishing a robust and scalable application infrastructure on the Amazon Web Services (AWS) cloud platform. To achieve this, we’re employing a combination of cutting-edge technologies and best practices.
What is our infrastructure?
The digital infrastructure is built on Amazon Web Services (AWS), a cloud computing platform that provides a wide range of online services to help businesses run their technology needs. Within this ecosystem, an EC2 functions as a remote server that we can lease from AWS. To power our application, we utilize Amazon Elastic Kubernetes Service (EKS). This service harnesses a cluster of EC2 instances, effectively creating a powerful, unified computing environment where all components of our application can operate seamlessly.
To ensure security, we’ve set up our system in a Virtual Private Cloud (VPC). Imagine this as a private, cordoned-off section of the internet just for our use. Within this VPC, we use private subnets, which can’t be directly accessed from the public internet, adding an extra layer of protection.
Our application itself is packaged into a Docker container. (See containerization)
We use these containers with Kubernetes. EKS is Amazon’s managed Kubernetes platform, which helps us deploy, scale, and manage our application efficiently within the AWS ecosystem. It can automatically start up more instances of our application when there’s high demand or scale down when demand is low, ensuring we’re using our resources effectively.
This combination of AWS, containerization, and Kubernetes allows us to have a flexible, scalable, and reliable setup for our application. It means we can quickly adapt to changing needs, ensure our application is always available to users, and efficiently manage our resources. For businesses, this translates to better performance, cost-effectiveness, and the ability to innovate rapidly in a secure environment.
To manage and maintain our complex infrastructure efficiently, we leverage Terraform as our Infrastructure as Code (IaC) tool to manage and provision our Amazon Web Services (AWS) resources. Terraform allows us to define and maintain our cloud infrastructure using declarative configuration files rather than manually setting up resources through the AWS management console or using scripts.
When using Terraform to manage infrastructure, it relies on a state file to track the current status of deployed resources. However, this approach presents challenges in collaborative environments. Two primary issues arise when multiple team members work on the same Terraform project concurrently:
- State File Storage and Accessibility
Issue: Terraform stores its state file locally by default, which can lead to inconsistencies and conflicts when multiple team members work on the same infrastructure.
Solution: Implement a remote backend using an AWS S3 bucket.
- Create the S3 bucket either manually or by using Terraform, and configure Terraform so that it cannot delete the bucket, to serve as the remote backend.
- This allows all team members to access the same, up-to-date state file.
- It also provides better security and backup capabilities for the state file.
- Concurrent State File Modifications
Issue: If multiple users attempt to modify the infrastructure (and thus the state file) simultaneously, it can lead to conflicts or corruption of the state file.
Solution: Implement state locking using an AWS DynamoDB table.
- Create a DynamoDB table (manually) to manage state locking.
- Configure Terraform to use this table for locking operations.
- When a user initiates a Terraform operation that could modify the state, it first acquires a lock in the DynamoDB table.
- This lock prevents other users from making concurrent modifications.
- Once the operation is complete, the lock is released.
- This mechanism ensures that only one person can modify the state at a time, preventing conflicts and maintaining data integrity.
But how do we even get the docker image of the application using CI?
For that, I used a CI/CD (Delivery) tool called Jenkins, an open-source automation server widely used for continuous integration (CI) and continuous delivery (CD) of software projects. Jenkins automates the parts of software development related to building, testing, and deploying, facilitating continuous integration and continuous delivery.
When developers push changes to the Git repository, Jenkins automatically initiates a pipeline process. This pipeline builds an artifact – essentially a computer-readable source code version. The pipeline’s configuration is stored alongside the application code in the Git repository, allowing us to leverage Git’s features for our automation setup.
For our Python-based application, Jenkins employs Pytest to run tests. The resulting artifact is a Docker image, as our application requires containerization.
Since our app relies on a MongoDB database, we have to verify all components’ functionality together. For that, and to mimic our production environment behavior as closely as possible, we use Docker Compose (A tool that enables us to run and manage multiple Docker containers simultaneously more easily) for testing. This allows us to run API calls via Pytest and verify that the expected changes occur in the database. Notice we use Docker Compose as a testing environment only for practice purposes. IRL we will use more complex tools.
And what about our CD? How does our application get continuously deployed to our cluster?
The final piece of our continuous delivery (CD) puzzle involves ArgoCD, a declarative GitOps CD tool for Kubernetes. When Terraform sets up the Amazon EKS cluster, it also initiates an ArgoCD deployment using Helm, a package manager for Kubernetes.
Helm charts are packaged configurations for deploying applications on Kubernetes. They act like recipes and contain all necessary YAML files defining an application’s structure and dependencies. Helm charts use templating to create dynamic, reusable manifests and support versioning and dependency management.
In the project, there are three git repositories:
- Do-it: the main application source code repository
- Do-it-infra: has the Terraform files for the infrastructure
- Do-it-gitops-config: contains the helm charts for the application and other services needed to run on the cluster
I created a Helm chart describing the application and stored it in the Do-it-gitops-config repository. ArgoCD watches for changes to this chart. When Jenkins deploys a new artifact, it also increments the tags in both the Do-it and Do-it-gitops-config repositories. When changes are detected in the Do-it-gitops-config repository, ArgoCD uses Helm to deploy or update the application on the Kubernetes cluster, providing a standardized, repeatable deployment process.
Basically, ArgoCD works by continuously monitoring our Git repository for changes in the desired application state. When a change is detected, ArgoCD automatically syncs these changes with our EKS cluster, ensuring that the deployed application always matches the desired state defined in our Git repository.
Here’s how it fits into our workflow:
- Terraform creates our EKS cluster as part of our infrastructure setup.
- As part of this process, Terraform uses Helm to deploy ArgoCD onto the cluster.
- ArgoCD is configured to watch our Git repository for changes to our Kubernetes manifests or Helm charts.
- When changes are pushed to the repository (for example, a new version of our application), ArgoCD detects these changes.
- ArgoCD then automatically applies these changes to our EKS cluster, updating our application to the latest version.
This setup completes our CI/CD pipeline:
- Jenkins handles the Continuous Integration (CI) part by building and testing our code, then pushing the Docker image to ECR.
- ArgoCD handles the Continuous Delivery (CD) part by automatically deploying the latest version of our application to our EKS cluster.
By using ArgoCD, we ensure that our Kubernetes cluster always reflects the desired state defined in our Git repository, providing a robust, automated, and version-controlled approach to application deployment. This GitOps approach enhances our ability to maintain consistency, roll back changes if needed, and keep a clear audit trail of all deployments.
In addition to our main application, the Do-it-gitops-config repository contains Helm charts for several critical supporting services:
- Grafana and Prometheus for monitoring
- EFK (Elasticsearch, Fluentd, Kibana) stack for logging
- Cert-manager for SSL/TLS certificate management
- NGINX Ingress Controller for routing
These services are deployed in different namespaces and are organized in an “App of Apps” pattern. This approach was chosen to connect these services logically as they are all required to run on the cluster continuously and may serve multiple applications beyond the main one. They provide a robust infrastructure for monitoring, logging, security, and traffic management that can serve multiple applications simultaneously.
Our architecture includes one more crucial component: AWS Secrets Manager. The Helm charts used to configure the applications running on my cluster are stored in a Git repository. However, some applications require secure password configuration, and it’s considered poor practice to store secrets in Git, even in private repositories.
My application depends on a MongoDB database, which is included as an umbrella chart (a chart containing other chart files). To avoid exposing the MongoDB password in the Git repo, I’ve implemented a solution using AWS Secrets Manager.
Here’s how it works: I store the passwords in AWS Secrets Manager. When Terraform sets up our EKS cluster, it can be used to create a Kubernetes secret that pulls its value from the AWS secret. Although this Kubernetes secret is only base64 encoded, accessing it would require cluster access, at which point secret exposure would be the least of our concerns.
This approach allows me to configure MongoDB to retrieve its login details from the Kubernetes secret, effectively keeping sensitive information out of the Git repository while maintaining secure access within the cluster.
And that’s it! I have to say that one of the most satisfying parts of being a DevOps is seeing your ideas and solutions evolve and become fully-fledged systems. It feels a bit like being an artist and seeing your completed piece for the first time, or like watching your child take their first steps (or at least, I think it does—I don’t have children).
I know that it’s a lot of information at once, and it can feel overwhelming, but you need to remember that you will be learning it over a few months. I reached this level at that time, and you have the potential to do the same.
Choose the path that feels right for you, but I recommend that you at least try the entry exams. You might surprise yourself with what you can achieve.
And good luck to all of you! Maybe I’ll see you in the office during the next bootcamp 😉
Until next time,
Yasmin


