Aurora DSQL Has Landed: AWS’s Serverless SQL Game-Changer
What if your PostgreSQL database could scale globally, eliminate downtime, and manage itself?
Aurora DSQL is AWS’s latest answer to the future of serverless data infrastructure. If you’re building high-availability systems or latency-sensitive apps, this new offering might just change how you think about databases.
If you’re working with data-intensive applications and care about scale, speed, and simplicity, there’s a new tool worth paying attention to.
At the 2024 AWS re:Invent conference, AWS officially unveiled a major advancement in its database offerings: Amazon Aurora DSQL.
I had the opportunity to attend the event in person and came across a dedicated session introducing this exciting new service.
Among the many announcements made at re:Invent this year, Amazon Aurora DSQL stood out as one of the most eagerly anticipated. In fact, many within the industry hailed it as one of the best launches of re:Invent 2024.
Aurora DSQL was officially launched during the recent AWS Summit in Tel Aviv, in June 2025. .
In this article, I’ll delve into the architecture, features, and some use cases of Amazon Aurora DSQL to help you understand its potential and how it can fit alongside your architecture, especially if you’re exploring DevOps as a Service best practices for scaling infrastructure without operational overhead.
Aurora DSQL Overview and Architecture
Amazon Aurora DSQL is a serverless, distributed SQL database designed for always available applications (4 – 9’s in a single-region mode, and 5 – 9’s in a multi-region configuration).
Aurora DSQL addresses customer requests for a relational database (currently PostgreSQL) that is easier to manage, scales up and down with workloads, and simplifies the creation of highly available multi-region and multi-AZ architectures.
It is positioned as an innovation that can transform the approach to data management and application scalability. Aurora DSQL naturally integrates into simplified AWS deployment strategies, where automation, speed, and resilience are core principles.
Let’s break down the different attributes of Aurora DSQL:
- Serverless database – Zero infrastructure management, elimination of the burden of patching, upgrades, and maintenance downtime.
This means developers and infrastructure maintainers can quickly create new, virtually unlimited-scale databases within minutes. - Distributed architecture – With its innovative active-active distributed architecture, Aurora DSQL offers a multi-region configuration, providing 99.999% availability and eliminating downtime due to a built-in failover mechanism.
- PostgreSQL compatibility – Allowing developers to rapidly build and deploy applications using familiar relational databases concepts, drivers, tools (psql), and frameworks they already know.
- ACID – Transactions in Aurora DSQL offer all ACID properties (Atomicity, Consistency, Isolation, and Durability).
The ACID properties are maintained even across multiple regions configurations.
Write operations are synchronously replicated across the different regions, allowing strongly consistent reads and writes.
Amazon Aurora DSQL is based on an active-active distributed architecture, allowing us to create single-region and multi-region database clusters.
A single-region configuration handles component failures or AZ disruptions without downtime, while a multi-region configuration handles scenarios of multiple AZ failures and even a regional disruption.
Aurora DSQL active-active architecture eliminates downtime due to a failover mechanism, making it easy to design for business continuity – a critical capability for teams aiming to build zero-downtime production environments.
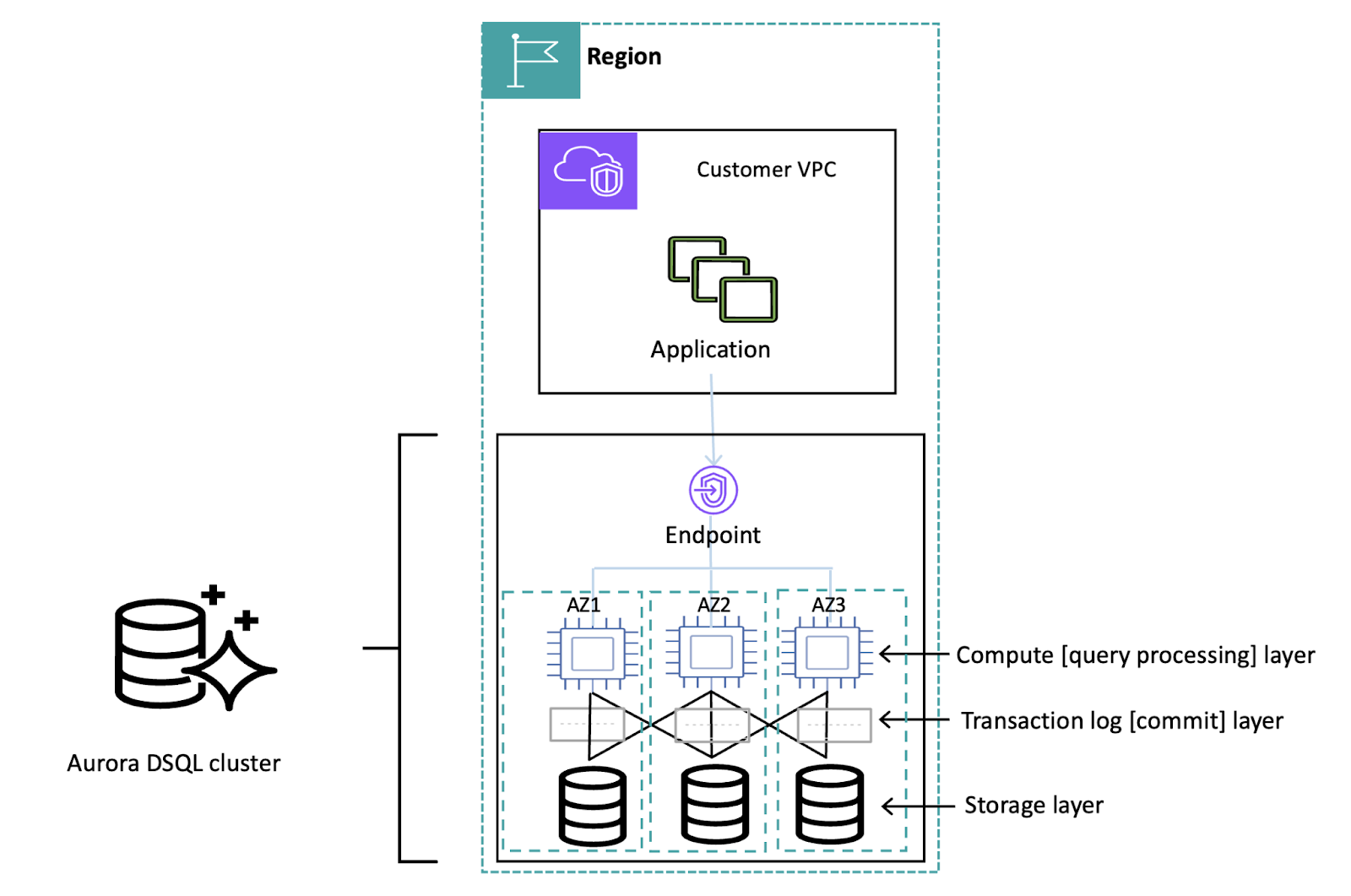
Figure 1- Source: AWS Aurora DSQL documentation, single region high-level architecture
In a single region configuration, DSQL commits all the write transactions log, and synchronously replicates all committed data to storage replicas in three availability zones.
Aurora DSQL is designed for automated failover recovery, for example, if an AZ becomes unavailable, Aurora DSQL automatically redirects traffic to the other healthy AZs.
Once the AZ is up and running again, Aurora DSQL automatically adds the previously failed availability zone back to the storage layer.
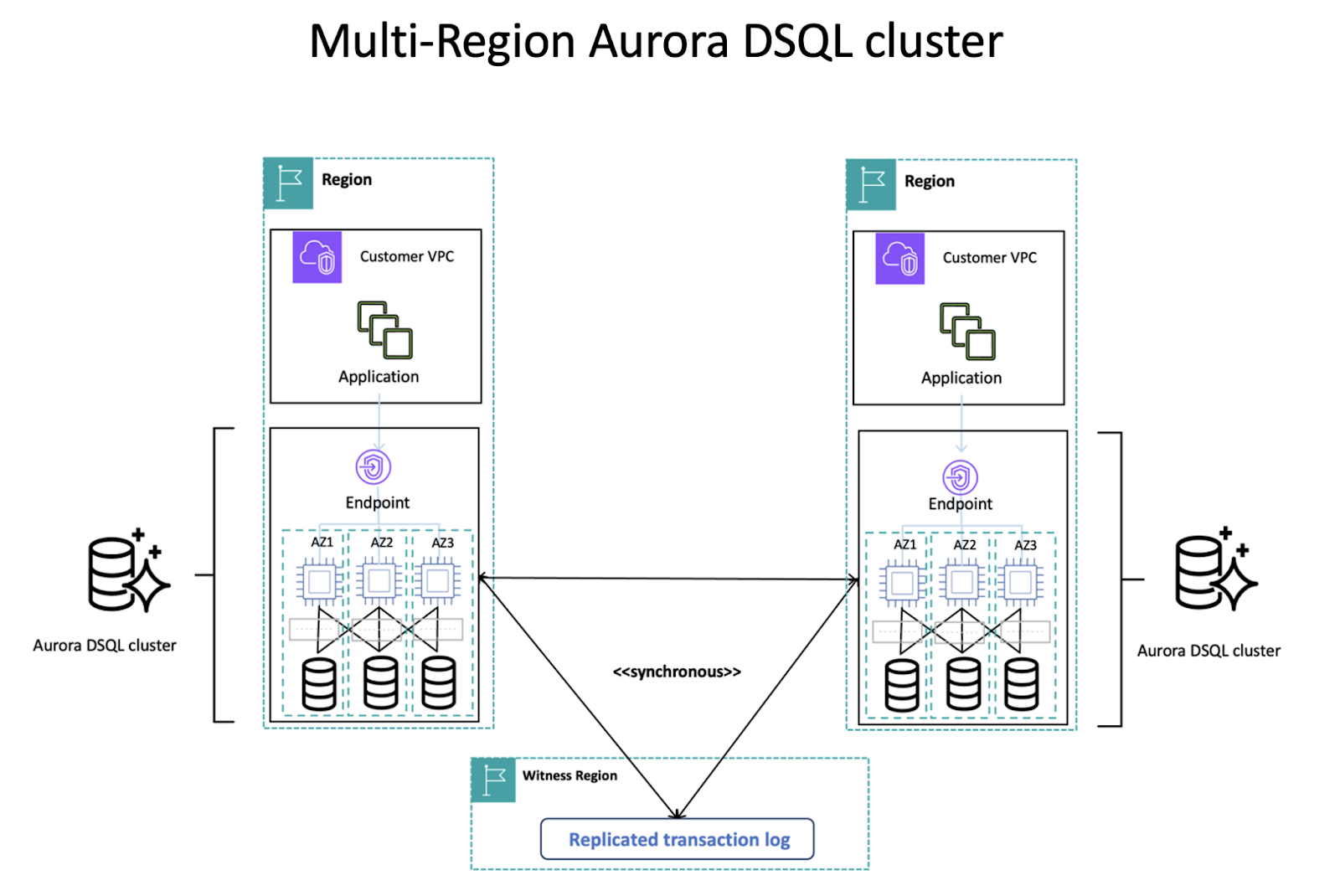
Figure 2- Source: AWS Aurora DSQL documentation (link), multi-region high-level architecture
With the same resilience and connectivity approach as in the single-region mode, the multi-region configuration enhances the overall availability of the database by provisioning two endpoints, one for each region.
Due to the DSQL active-active, strongly consistent read and write architecture, the data between regions stays synchronized at all times – all transactions are committed in all regions of the Aurora cluster, making it a great choice for applications that require data to be served based on geo-location for low latency.
Additionally, the failover mechanism, which operates in a multi-region configuration, enables us to recover and eliminate downtime in the event of a regional failure.
A third region (witness region) receives the data written to linked clusters, but doesn’t have a cluster endpoint; it is used by Aurora DSQL for storing a limited window of encrypted transaction logs, to provide Aurora DSQL multi-region durability and availability.
Real-World Use Cases for Aurora DSQL
With all the different features of Aurora DSQL mentioned above, there are some real-world use cases that can benefit from using this kind of database service.
- When there is a need for a structured database solution that has a minimal cost of maintenance.
Due to its serverless nature, Aurora DSQL is great for any use case that requires a seamless operational overhead of scaling up and down databases, upgrading, or patching operations. - Low-latency applications.
As mentioned above, Aurora DSQL offers a multi-region configuration, making it a perfect solution for applications that require a geo-based, low-latency, structured (PostgreSQL) database. - Critical systems that require a very high availability at all times.
When there is a need for a robust DR-oriented solution or a critical product, Amazon Aurora DSQL provides us with the highest possible availability rates database (PostgreSQL compatible) solution available, offering 99.99% availability in a single-region configuration and 99.999% availability in a multi-region mode.
Aurora DSQL can also complement your DevOps readiness assessments by providing a resilient data layer from the start – and that’s exactly what makes it a game-changer for teams who can’t afford downtime.
Whether you’re building a low-latency application, designing for regional resilience, or simply seeking a PostgreSQL-compatible database that scales seamlessly, Aurora DSQL offers a compelling solution.
To evaluate its fit, consider identifying a workflow where availability or scalability is currently a challenge, and test Aurora DSQL in that context. You may find that its architecture simplifies complexity while delivering the availability guarantees modern systems demand.



