
Bitbucket Server to Github Cloud Migration
My Client needed a way to migrate from Bitbucket server to GitHub cloud. Migrating from Bitbucket Server to GitHub Cloud sounds like a challenging task, but not too complex, hey it’s just git clone and git push right?
Oh man, I wish… who thought that getting a reviewer email from PR in Jenkins CI would cause so many problems?
So what are we going to learn from this article?
- How important is the planning?
- Challenges that I’ve experienced.
- How did I handle the code freeze?
- Invite bulk users and add them to the necessary teams.
Preparation and Planning
Initial Assessment:
Our Bitbucket Server setup consisted of numerous repositories, including large test data repositories, extensive CI/CD configurations, and customized API integrations. The primary challenge was to transition these components seamlessly to GitHub Cloud.
Tools and Resources:
We planned to use git-filter-repo to clean up the repositories and in the beginning I migrated to AWS S3 for handling large data sets, in the end, I used Github LFS. Additionally, we needed to adapt our CI/CD systems and API calls to work with GitHub.
Key Challenges and Solutions
Repository Size and File Management:
GitHub enforces a 100 MB limit per file, which required us to rethink how we managed large files. Initially considering Git LFS, after that we decided to use AWS S3 for storing large test data files. This solution involved setting up a VPC endpoint and policy to securely access the S3 bucket through our VPN, ensuring both the CI system and developers could access the necessary data. In the end, i’ve used both Github LFS and S3 bucket. For the Github LFS I had to use git-filter-repo to remove and then add them to the lfs. example : git filter-repo --path file_name.zip --path .gitattributes --invert-paths and then add them to .gitattributes echo "file_name.zip filter=lfs diff=lfs merge=lfs -text" > .gitattributes You can read more at – Migrating Bitbucket Server Repositories to GitHub: A Step-by-Step Guide
Code Ownership Management:
We found that GitHub’s CODEOWNERS file operates differently than Bitbucket’s equivalent. Specifically, GitHub requires using organization teams for code ownership. This necessitated restructuring our approach to maintain proper code reviews and permissions.
CI/CD Integration:
Our existing CI setup in Bitbucket did not require authentication for certain operations, as it was within the same VPC as our Jenkins agents. However, with GitHub, we needed to configure authentication for cloning, pushing, and other operations, ensuring secure and efficient pipeline execution.
Also, we needed a Webhook for our Jenkins inside a private subnet, In additional to that we needed a way to trigger it manually, inside Github UI PR and i ended up creating a button for it. You can read more at Optimizing CI Costs: Manual Jenkins Build Trigger from GitHub Actions
API Changes:
Our CI is using a lot of API Calls and the transitioning from Bitbucket’s API to GitHub’s API presented challenges due to differences in structure and response formats. This required a complete overhaul of our API interaction layer, affecting both our CI pipelines and internal applications. During this transition, we had to manage ongoing development work, which included structural changes to the application and codebase. The client uses Jenkins shared library so it wasn’t a problem to change without effect the continuous development.
Data Management in CI/CD:
Our CI/CD pipelines relied heavily on a large repository of test data in Bitbucket. To overcome GitHub’s file size limitations, we moved some data to AWS S3 and some to Github LFS. We also created a VPC endpoint and policy, allowing both the CI system and developers to securely access the test data from S3.
GitOps Integration with ArgoCD:
We had an existing setup with ArgoCD in our EKS cluster for GitOps deployments, which did not require authentication for accessing repositories in Bitbucket. Post-migration, we had to configure authentication for GitHub to ensure secure access and deployment management through ArgoCD. This required updating the configurations and credentials in ArgoCD to align with GitHub’s authentication mechanisms.
GitHub Email Accessibility:
In our CI processes, we send reports to reviewers and the author of a pull request. GitHub’s privacy settings presented a challenge, as user emails are private by default. To access these email addresses, we needed to either request users to make their emails public or subscribe to GitHub Enterprise to access verified email addresses. This added a layer of complexity to our CI workflow, requiring careful consideration of privacy and cost implications.
In the end, we decided to go with GitHub Enterprise not only for security reasons but also for management, settings, and configuration reasons. (Of course, we needed to change our Groovy inside our Jenkins shared libs to take the verified emails of the reviewers.)
Migration Process
Cleaning Up the Repository:
Using git-filter-repo, we meticulously removed unnecessary files, large files, and outdated branches to streamline the migration process.
Testing and Validation:
Post-migration, we conducted thorough testing to ensure the integrity of the repositories and the proper functioning of our CI/CD pipelines, API integrations, and GitOps workflows with ArgoCD.
Migration Day
Ahead Of Migration Day :
We needed to configure a few things before the migration days.
2. Add all users to the GitHub Organization :
- Add users via Okta to the enterprise.
- Extract unaffiliated users.
# CSV report from https://github.com/enterprises//people?query=role%3Aunaffiliated
import pandas as pd
# Load the CSV file
csv_file = './all-users.csv' # Replace with the path to your CSV file
df = pd.read_csv(csv_file, delimiter=',') # Adjust delimiter if needed
# Print column names for debugging
# print("Columns in DataFrame:", df.columns.tolist())
# Trim any extra spaces from column names
df.columns = df.columns.str.strip()
# Check if 'GitHub com enterprise roles' exists after trimming
if 'GitHub com enterprise roles' in df.columns:
filtered_df = df[df['GitHub com enterprise roles'] == 'Unaffiliated user']
unaffiliated_users = filtered_df['GitHub com login']
# Save to text file
unaffiliated_users.to_csv('unaffiliated-users.txt', index=False, header=False)
else:
print("Column 'GitHub com enterprise roles' not found.")
- Add the unaffiliated users from Github enterprise to GitHub Org.
2. Teams
- Configure all the teams inside GIthub Organization.
#!/bin/bash
#Add the unaffiliated users from Github enterprise to GitHub Org
ORG="ORG_NAME"
user_file="unaffiliated-users.txt"
#example for user_file - `unaffiliated-users.txt`
#rotem_user_name
#rotem2_user_name
if [[ ! -f $user_file ]]; then
echo "$user_file not found!"
exit 1
fi
# Loop through each line in user file
while IFS= read -r username; do
echo "Inviting $username to the organization $ORG..."
# Use GitHub CLI to invite user
gh api \
--method PUT \
-H "Accept: application/vnd.github.v3+json" \
"/orgs/$ORG/memberships/$username" \
--silent
if [[ $? -eq 0 ]]; then
echo "Successfully invited $username."
else
echo "Failed to invite $username."
fi
done < $user_file
- Add all of the users to their teams.
#!/bin/bash
ORG=""
USER_ROLE="member" # Can be changed to maintainer.
# Define the path to your JSON file
JSON_FILE="users-to-team.json"
# Example input file: users-to-team.json
#{
# "test22-team": ["rotem_user_name"],
# "textxxx-team": ["rotem_user_name", "rotem2_user_name"]
#}
# Iterate through each team and its users
jq -c 'to_entries[]' "$JSON_FILE" | while IFS= read -r entry; do
# Extract team name and users from JSON
TEAM_NAME=$(echo "$entry" | jq -r '.key')
USERS=$(echo "$entry" | jq -r '.value[]')
# Add each user to the team
for USER in $USERS; do
echo "Adding user $USER to team $TEAM_NAME"
gh api --method PUT \
-H "Accept: application/vnd.github+json" \
-H "X-GitHub-Api-Version: 2022-11-28" \
/orgs/"$ORG"/teams/"$TEAM_NAME"/memberships/"$USER" -f "role=$USER_ROLE"
done
done
3. Jenkins
- Tokens and permissions to GitHub repositories.
Automation:
Because we change a lot of configuration in the CI, Code itself, CODEOWNERS and etc. We have to test the CI, and CD after the migration. The problem is :
- Code Freeze – While migrating between Bitbucket and Github, do we need to shut down all of the company for the migration? It cost a lot. So a lot of questions came up.
- CI CD Flow – does the CI work fluently now? Are there errors?
- Important – the CI of a few of the applications require testing, and some of the testing can take up to 2 hours for a single pipeline job.
- The CI checks file changes and triggers accordingly.
- Does all the users have access to their repositories?
- What about repositories settings?
Our Solution?
Create a sync job that does all of the above in the night just before the workday.
We sent before the migration day a few details about it, like – until when he can push and what will be migrated.
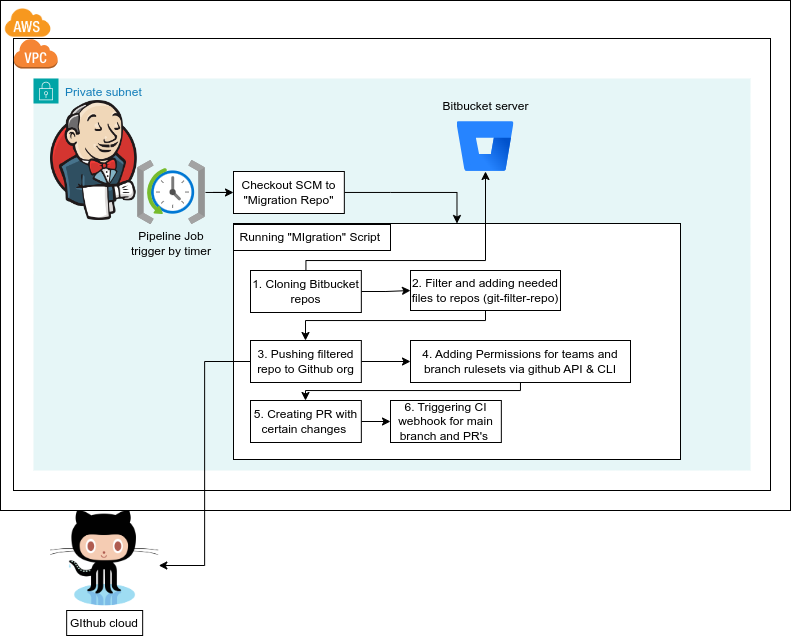
Migration Job: What does the Migration job do?
Migration Job is a pipeline that uses Groovy and custom script to:
1. Triggered at night
2. Migrate between Bitbucket to Github.
3. While migrating the repositories: all of the below with a script that uses Github CLI.
- Adding Rulesets with JSON files. example :
gh api "/repos/$organization/$repo/rulesets" --method POST --input file_name.json
- Adding Permissions for the teams to access the repo (We already added the users to the teams)
# Short example inside my script loop :
JSON_FILE="repositories.json"
organization=""
# Example for input file : repositories.json
#{
# "repositories": {
# "some_repo": {
# "main_branch": "master",
# "clone_url": "bitbucket_url",
# "split_repo": "true",
# "teams": {
# "maintain": [
# "Maintainers"
# ],
# "push": [
# "teams22"
# ],
# "pull": [
# "example_pull"
# ],
# "triage": [
# "example_triage"
# ]
# }
# }
# }
#}
repositories=$(jq -c '.repositories' "$JSON_FILE")
# Loop through repositories
echo "$repositories" | jq -r 'keys[]' | while read -r repo; do
main_branch=$(echo "$repositories" | jq -r ".[\"$repo\"].main_branch")
teams=$(echo "$repositories" | jq -r ".[\"$repo\"].teams")
clone_url=$(echo "$repositories" | jq -r ".[\"$repo\"].clone_url")
split_repo=$(echo "$repositories" | jq -r ".[\"$repo\"].split_repo") #for git-filter-repo and big repositories
# Loop through each permission and extract corresponding team names
permissions=$(echo "$teams" | jq -r 'keys[]')
for permission in $permissions; do
team_names=$(echo "$teams" | jq -r ".[\"$permission\"][]")
for team_name in $team_names; do
echo_in_color "$GREY" "Repository: $repo, Main Branch: $main_branch, Permission: $permission, Teams: $team_name"
gh api --method PUT \
-H "Accept: application/vnd.github+json" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"/orgs/$organization/teams/$team_name/repos/$organization/$repo" \
-f "permission=$permission"
done
done
done
- Open 3 PRs
- For Releases, Main Branch and merged them.
- PR Tests for specific files to trigger specific CI tests.
Example :
# Open PR to Tests Jenkins CI.
git -C ./$repo checkout "$main_branch"
git -C ./$repo pull origin "$main_branch"
git -C ./$repo checkout -b "$pr_test_branch_name"
# Adding Echo to trigger Tests
echo "" >> ./$repo/<path_to_file>
echo "" >> ./$repo/<path_to_file2>
echo "" >> ./$repo/<path_to_file3>
git -C ./$repo add .
git -C ./$repo commit -am "Sync Commit"
git -C ./$repo push -u origin "$pr_test_branch_name"
gh pr create \
--repo "$organization/$repo" \
--base $main_branch \
--head "$pr_test_branch_name" \
--title "$pr_test_branch_name" \
--body ""
Then Trigger the Jenkins Pipeline :
PAYLOAD="{\"TOKEN\": \"$repo\"}"
curl -XPOST $Lambda_Webhook_Link -d "$PAYLOAD"
PR_NUMBER_TESTS="PR-3"
PAYLOAD="{\"MERGED_TO\": \"$PR_NUMBER_TESTS\", \"MULTI_BRANCH_NAME\": \"$repo\"}"
curl -XPOST $Lambda_Trigger_Job_Link -d "$PAYLOAD"
more about the trigger check – Optimizing CI Costs: Manual Jenkins Build Trigger from GitHub Actions
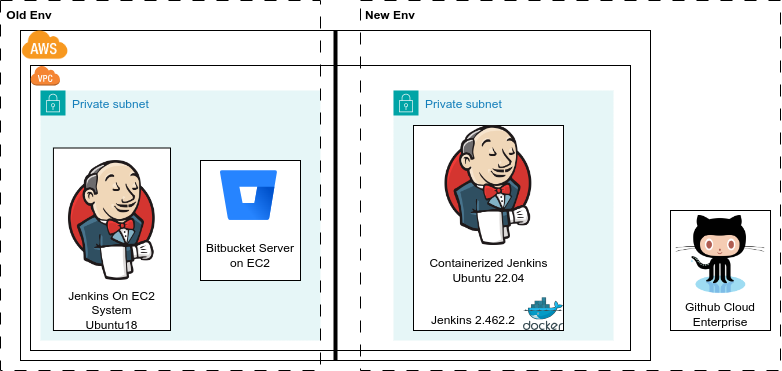
Jenkins part:
Simultaneously, we undertook a significant modernization of our Jenkins infrastructure. The existing Jenkins server was running on an Ubuntu 18 instance, which we migrated to a containerized Jenkins setup. This approach offered greater flexibility, scalability, and ease of management. As part of this process, we also upgraded Jenkins to a newer version and updated the system to Ubuntu 24, benefiting from improved performance, security updates, and long-term support.
We moved to a containerized Jenkins environment for couple of reasons.
- Scalability
- Isolation and Consistency
- Simplified Management and Deployment
- Resource Efficiency
- Faster Recovery and Updates
its allowed us to leverage container orchestration, making our CI/CD system more resilient and easier to scale. It also simplified the management of Jenkins configurations and plugins, which now follow a more modular, repeatable deployment process.
Using Terraform to Manage Containerized Jenkins
To manage our containerized Jenkins infrastructure, we chose Terraform. Here’s how we used Terraform in the process:
- Infrastructure as Code: Terraform enabled us to define Jenkins infrastructure as code, ensuring a consistent and repeatable deployment process across different environments. All components, including containers, networking, and storage, were declared in code.
- Automated Provisioning: We automated the provisioning of the underlying infrastructure, such as EC2 instances for running the Jenkins containers, storage volumes for persistent data, and networking configurations. Terraform’s ability to apply infrastructure changes in a predictable and automated manner greatly reduced manual effort.
- CloudWatch Alarms for Disk Usage: In addition to setting up the core infrastructure, we used Terraform to configure CloudWatch alarms for monitoring disk usage. these alarms help ensure the Jenkins environment runs smoothly by alerting us if disk usage exceeds a certain threshold, allowing us to respond proactively to prevent service interruptions. This level of monitoring was critical as it helped maintain the reliability of our CI/CD pipeline.
- Modular Approach: We used Terraform modules to encapsulate various infrastructure components. This modular approach made it easy to manage and scale our Jenkins setup, as each component (e.g., storage, networking, compute) was isolated and could be reused or modified independently.
- Version-Controlled Infrastructure: With Terraform, we could version-control not only the Jenkins setup but also the entire infrastructure stack. This allowed us to track changes, roll back configurations when necessary, and ensure consistency across environments.
- Seamless Updates: Whether upgrading Jenkins, adjusting resource allocations, or deploying new infrastructure, Terraform made the process seamless. We could update our infrastructure code, run a plan to see the proposed changes, and apply them with confidence, minimizing downtime and disruption to our CI/CD pipelines.
By integrating Terraform into our containerized Jenkins workflow, we ensured an automated, scalable, and resilient setup that aligns with our DevOps practices and cloud-native strategy.
You can read more about it at Build a Resilient Containerized Jenkins CloudWatch Disk Monitor with Terraform
Lessons Learned
Flexibility and Adaptation:
The migration underscored the importance of being adaptable to new tools and systems. Our team had to quickly learn and implement GitHub-specific features and workflows, especially in the context of CI/CD and GitOps practices.
Documentation and Team Coordination:
Effective documentation and clear communication were vital in managing the migration, especially with ongoing development work. This ensured all team members were aligned and any issues promptly addressed.
Migration Day technical problems:
During the migration, we encountered significant technical problems while cloning our repository. Given the large size of the repository and the high traffic through our office network, we frequently received the following error:
early EOF
fatal: The remote end hung up unexpectedly
Solutions Implemented
The first solution was to increase the Git post buffer size using the following command:git config --global http.postBuffer 524288000
Additionally, we used a mobile hotspot due to internet speed limitations in the office. While this helped, some team members still faced cloning issues. The extended solution included the following steps:
git config --global http.postBuffer 524288000
git config --global core.compression 0
git clone --depth 1 <repo_URI>
git fetch --unshallow
git fetch --depth=2147483647
git pull --all
Fixing Branch Tracking Issues
After resolving the cloning issues, we encountered a problem where local branches only tracked the master branch. To fix this, we manually edited the Git configuration file (.git/config) and changed the fetch rule under the [remote "origin"] section.
Original line: fetch = +refs/heads/**master**:refs/remotes/origin/**master**
Modified line: fetch = +refs/heads/******:refs/remotes/origin/******
After this change, running git fetch allowed us to pull all remote branches.
Conclusion
Outcome:
The migration to GitHub Cloud was successful, resulting in a more scalable, secure, and collaborative environment. The transition to GitHub LFS for test data storage and restructuring our CI/CD pipelines have improved efficiency and reduced maintenance overhead. The integration of GitHub with ArgoCD for GitOps deployments has further streamlined our development and deployment processes.
We optimized Jenkins Master cost by implementing our webhook to scan new PR and branch by manual trigger.
We successfully lowered the cost of the code freeze by implementing a migration script that will run in the middle of the night and not shut down work hours.
Future Work:
We plan to continue optimizing our use of GitHub features and explore further integrations with cloud services to enhance our development and deployment processes.



