
Streamlining ML Workflows: Integrating Databricks with GitHub Actions
When it comes to managing and deploying models efficiently, navigating the machine-learning realm can often feel like traversing through a maze. This article presents an integration between Databricks and GitHub Actions, which emerged as a beacon of simplicity among often convoluted ML workflows. With the robustness of Databricks combined with the automation capabilities of GitHub Actions, this integration not only refines the version control process, which is a fundamental component of tracking model iterations but also cultivates a fertile terrain for collaboration among data science teams. In this story, you will learn how this fusion can impact your machine-learning endeavors, acting as a catalyst for streamlined workflows and accelerating innovation.
What is Databricks
Databricks is a cloud-based platform revered for its capabilities in data engineering, analytics, and machine learning at an enterprise scale. Originating from the creators of Apache Spark, Databricks facilitates the processing and analysis of large data quantities through its unified, open analytics platform. By melding data lakes and data warehouses into a ‘lake house’ platform, Databricks offers automated management and seamless interaction with cloud infrastructure, making it a go-to solution for easy deployment of analytics and machine learning workflows.
The GitHub Integration Rationale
The necessity of integrating with GitHub stems from the requirement of having well-structured ML workflows. This ensures not only the up-to-date status of models but also their correct versioning. By utilizing model names and versions from Databricks, teams can pass them to a central artifact repository like Jfrog Artifactory, providing a structured and version-controlled repository for ML models. Databricks’ Webhooks feature is a pivotal component in this integration. These webhooks, designated per model, facilitate automation by incorporating information about our model and forwarding it. However, a direct dispatch to GitHub is untenable as the dispatch action API’s scheme differs from Databricks’ payload. Thus, creating a listener as a mediator is essential.
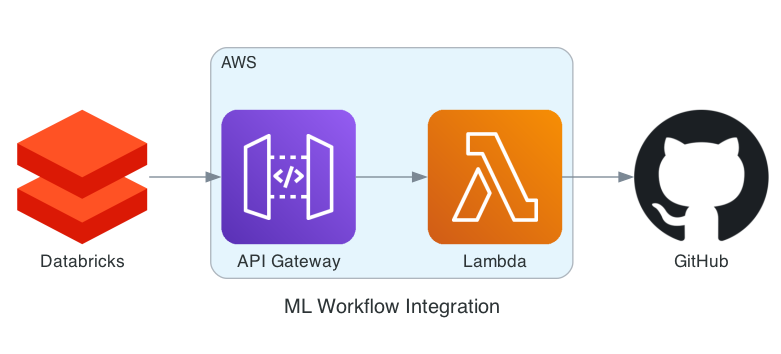
API Gateway and Lambda Function Creation
The integration’s cornerstone is a Lambda function that channels information from our webhook to GitHub. Initially, an API gateway of type REST, which is edge-optimized, is created to ensure the endpoint’s continuous availability. Following this, a Lambda function is deployed that activates POST requests to our gateway, forming the bridge between Databricks and GitHub.
Payload Transformation
The payload transformation is crucial for ensuring the correct data is sent to GitHub. The JSON Payload from Databricks needs to be transformed to match GitHub’s expected payload format.
JSON Payload of our DataBricks webhook:
{
"event": "MODEL_VERSION_TRANSITIONED_STAGE",
"webhook_id": "c5596721253c4b429368cf6f4341b88a",
"event_timestamp": 1589859029343,
"model_name": "Airline_Delay_SparkML",
"version": "8",
"to_stage": "Production",
"from_stage": "None",
"text": "Registered model 'someModel' version 8 transitioned from None to Production."
}JSON Payload for Github:
{
“ref”: OUR_MAIN_BRANCH,
“inputs”: {
“model_name”: OUR_MODEL_NAME
“model_version”: OUR_MODEL_VERSION
}
}Dynamic Workflow Creation
The dynamic passing of parameters into our GitHub workflow is pivotal for creating a flexible and adaptable workflow. The use of the ‘workflow_dispatch’ event allows for the passing of necessary information regarding the ML model name, version, and any other parameters from Databricks, adding a layer of dynamism to the workflow management.
Lambda Code Breakdown
The Lambda function serves as the mediator, ensuring the correct transformation and transmission of data between Databricks and GitHub.
import json
import requests
def lambda_handler(event, context):
databricks_payload = event
github_payload = {
"ref": "master",
"inputs": {
"model_name": databricks_payload["model_name"],
"model_version": databricks_payload["version"]
}
}
headers = {
"Accept": "application/vnd.github+json",
"Authorization": "Bearer PAT_TOKEN",
"X-GitHub-Api-Version": "2022-11-28"
}
response = requests.post(
'https://api.github.com/repos/OWNER/REPO/actions/workflows/WORKFLOW_ID/dispatches',
headers=headers,
data=json.dumps(github_payload)
)
return {
'statusCode': response.status_code,
"response": response.text
}
׳׳׳PAT_TOKEN: the developer token you need to create and give the permissions to run your workflows.
OWNER/REPO: the repository path
WORKFLOW_ID: can be taken from the api request of list workflows inside your repository.
Even though our Lambda function does not necessitate a return value, providing a return statement enhances our logs within AWS CloudWatch. By returning the status code and response text, we enrich our log data, which is instrumental for monitoring and troubleshooting the integration pipeline, ensuring its robust and reliable operation. This practice aligns with maintaining a well-monitored and observable system, fostering a proactive approach to identifying and resolving issues.
Disclaimer: For those utilizing GitHub Enterprise with a Whitelist of IPs, attaching the lambda to the VPC whitelisted for personal use is an option worth considering.
Setting Up a Model Webhook using Postman
The integration of Databricks with existing CI/CD tools and workflows can be streamlined through the utilization of webhooks that listen for Model Registry events. While Databricks documentation does not provide direct instructions on using Postman for this purpose, the process can be inferred from general Postman usage and the provided curl command.
In the URL field, enter the endpoint for the Databricks REST API followed by the webhook path, for example: https://<databricks-instance>/api/2.0/mlflow/registry-webhooks/create.
In the Headers section, add a key named Authorization and set the value to your Databricks access token (e.g., Bearer <access-token>).
In the Body section, switch to raw input and select JSON (application/json) as the text format.
Enter the JSON payload for the webhook configuration as follows:
{
"model_name": "<model-name>",
"events": ["MODEL_VERSION_CREATED"],
"description": "Slack notifications",
"status": "TEST_MODE",
"http_url_spec": {
"url": "https://hooks.slack.com/services/...",
"secret": "anyRandomString",
"authorization": "Bearer AbcdEfg1294"
}
}Conclusion
Orchestrating a straightforward, linear ML workflow is paramount for the effective management and deployment of machine learning models. This custom integration between Databricks and GitHub Actions delineated in this article paves the way for simplified, automated, and version-controlled ML workflows. By mitigating complexities and fostering a structured workflow, data science teams can focus more on model development, evaluation, and deployment, rather than being bogged down by workflow orchestration challenges. This not only accelerates the model delivery process but also ensures that the ML models are reliable, traceable, and up to the requisite standards, thereby significantly contributing to the operational efficiency and success of machine learning projects.